Opera One Browser Revolutionizes AI Experience with Local LLM Support
In a bold move that could reshape the landscape of browser-based artificial intelligence, Opera has announced the integration of local large language model (LLM) support within its Opera One browser. This groundbreaking feature allows users to run a staggering array of 150 LLMs directly on their own devices, marking a significant departure from the traditional reliance on remote servers.
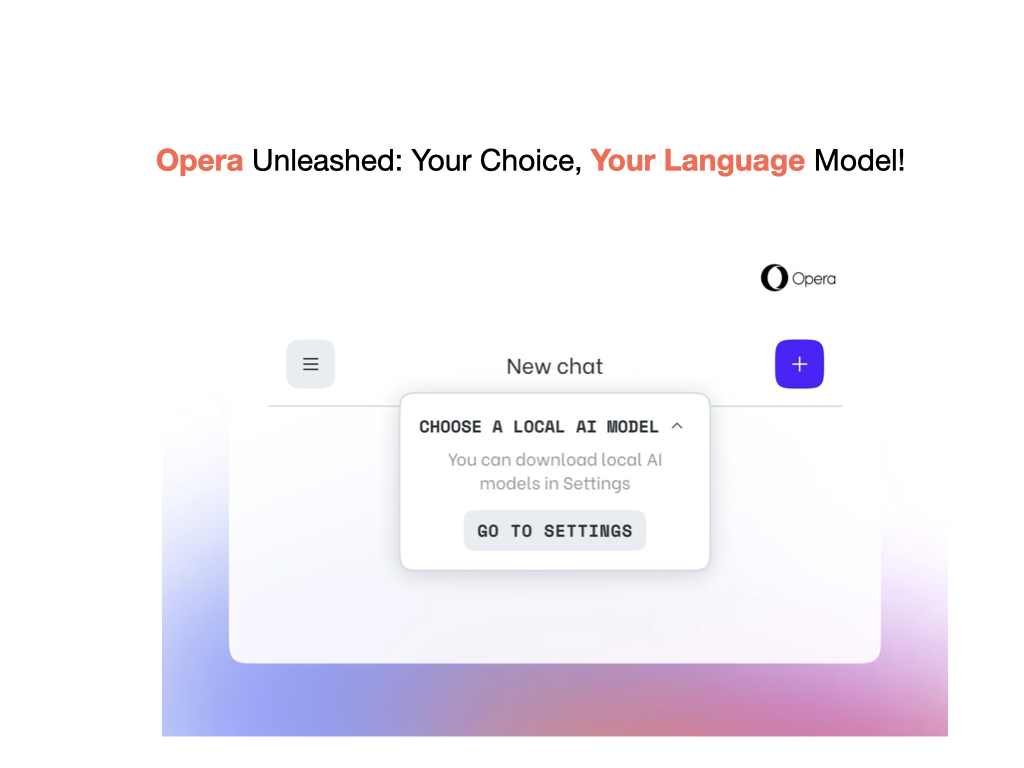
The announcement, made on the Opera Blogs, has sent shockwaves through the tech community, as it addresses longstanding concerns over privacy and efficiency in AI-driven interactions. Typically, when users engage with LLMs like ChatGPT, their queries are sent to remote servers for processing, raising potential privacy issues and introducing latency. However, with the advent of powerful AI-enabled PCs, Opera has seized the opportunity to empower users with the ability to run these models locally.
According to the blog post, the Opera One browser will support LLM families from a diverse range of sources, including the Llama model from Meta, Vicuna, Gemma from Google, and the Mixtral model from Mistral AI, among many others. This extensive library of 150 LLMs, spanning around 50 distinct families, offers users an unprecedented level of choice and flexibility in their AI-driven experiences.
The move by Opera stands in stark contrast to the recent actions of its competitors. While Microsoft has rebranded its mobile browser as “Microsoft Edge: AI Browser” and Google Chrome has introduced AI-generated themes, Opera has taken a bold leap forward by integrating local LLM support directly into its browser.
This innovation has the potential to reshape the way users interact with AI-powered features, addressing concerns over privacy and efficiency. By processing LLM queries locally, the Opera One browser reduces the need to send sensitive information to remote servers, mitigating potential privacy breaches and enhancing the overall user experience.
Moreover, the ability to run LLMs locally holds the promise of improved performance and responsiveness, as users no longer have to contend with the latency associated with remote server processing. This could be particularly beneficial for time-sensitive applications or scenarios where seamless, real-time interactions are crucial.
The introduction of local LLM support in the Opera One browser sets a new standard for privacy and efficiency in the AI-driven web landscape. As competitors scramble to catch up, it remains to be seen how this move by Opera will shape the future of browser-based artificial intelligence and the user experience it offers.